第10期 · 腾讯IEG光子一面
腾讯 IEG 光子 一面 4.23 11:00-12:00
八股
Vue 的 DIFF 算法核心是什么,具体怎么实现
无论是 Vue2、Vue3,还是 React,它们在对比两棵树时,都是“同层比较”。如果同一层级的节点类型(如 div 变成了 span)或 key 发生了变化,它们都会直接销毁旧节点、创建新节点,不再继续向下深度比较。

大模型
上下文工程演变历程
上下文工程的本质是【如何更高效地管理大模型的短期显存】,主要经历了以下五个阶段:
1. 意图对齐期:Few-Shot (少样本学习)
痛点:纯零样本(Zero-shot)下,模型输出的格式和语气易跑偏,不符合业务预期
方案:在上下文中预置 2-3 个标准 Q&A 样例,模型无需微调即可通过类比完成任务
2. 容量突破期:RAG (检索增强生成)
痛点:早期模型 Token 窗口小(4K-8K),无法直接塞入长文档或私密数据,易产生事实幻觉
方案:引入向量数据库(Vector DB)。在喂给大模型前先进行语义检索,取出最相关的切片(Top-K Chunks),按需拼接进上下文
3. 降本提效期:压缩与缓存 (Compression & Caching)
痛点:128K+ 超长窗口带来副作用:1)中间细节丢失(Lost in the Middle);2)Token 费用高昂;3)首字响应(TTFT)极慢
方案:【信息压缩】引入小模型(如 LLMLingua)提前剔除无用停用词,实现信息浓缩。【物理缓存】利用 Prompt Caching 技术,将长期不变的系统提示词或长文档固化在 GPU 显存池中,命中后实现降本及秒级响应
4. 架构隔离期:多智能体编排 (Agentic Workflow)
痛点:复杂任务下,将多轮历史、旧目标、报错栈全塞入单一上下文,会导致模型逻辑错乱(即上下文污染 Context Pollution / 上下文腐化 Rot/ 上下文衰减 Decay)
方案:从“单体巨石”转向“微服务”。拆分多 Agent,实施上下文局部隔离(例如:Planner 只看宏观需求,Coder 只看当前函数)。引入草稿纸(Scratchpad)机制隔离推演过程与最终输出
5. 跨会话感知期:持久化记忆 (Stateful Memory)
痛点:模型底层无状态(Stateless),跨级、跨会话的历史经验无法继承,需反复输入背景信息
方案:引入全自动化记忆层。在后台静默提取用户偏好构建【特征图谱】,当用户开启新会话时,系统利用语义检索精准激活历史记忆,前置拼装为用户的上下文
skill 是直接传给底层大模型嘛
不会直接生传,通常经过如下中间件:
意图路由引擎:判断当前任务是否需要使用特定的 skill
文本解析与 Chunking:如果 Markdown 内容长,会切片或者转换为结构化提示
RAG 向量检索:如果是知识型 skill,会被作为外部知识存入向量库检索
Prompt Builder(拼装器):将 user query, rules(系统规则), history(记忆)和截取的 skill.md 内容动态组装进最终的 Prompt payload 中,提交给 LLM
AI 与人如何协作
人做架构与审查,AI 做填空与执行(Copilot 模式)
AI 负责: 繁琐样板代码生成、文档编写、单测补充、海量日志初步排错
人类负责: 核心业务逻辑设计、边界条件定义、架构选型、最终 Safety Review
信任但验证(Trust but Verify): 将 AI 视为【高智商但容易粗心的应届生实习生】
AI 时代怎么学习知识,怎么学会知识
这个问题很诡异,我说通过与 AI 对话快速获取知识,面试官说【AI 像是老师,老师讲完之后你怎么学习并把知识化为自己的】,那我就说可能通过 NotebookLM 之类的工具提高做笔记的效率,不确定是否回答到点子上……
Rules、Memory 和 Harness 的区别
Rules 是指导大模型行为的系统级约束与准则(System Prompt),核心作用是限制行为边界和指导输出风格。不会因为你当前在开发什么项目而改变,规定了 AI【能做什么、不能做什么、以什么语气做】
设定 AI 必须使用 TypeScript 强类型,禁止使用 any 标注;要求所有 UI 组件必须优先使用 Tailwind CSS 类名而不是内联样式;规定生成的代码中必须要包含 JSDoc 注释等。这些属于强制遵守的法则
Memory 是 AI 对当前环境的认知和历史记录,它的核心作用是提供上下文,解决【我是谁、我在哪、我在做什么】的问题。Memory 是动态的,随着你的操作不断更新
实例:
短期记忆包含你和 AI 的前 10 轮对话历史,以及当前编辑器里高亮选中的那十几行代码
长期记忆(RAG 知识库)则是 Cursor 在底层把你整个项目的万行代码、路由结构解析后存入的本地向量数据库
Harness 是隐藏在模型背后的工程化执行与验证外壳
实例:
当大模型生成一段代码后,Harness 会在后台利用 Language Server Protocol(LSP)悄悄进行语法检查,如果发现有类型未引入或拼写错误,Harness 会自动把错误信息发回给大模型让它重新修改,然后再把最终正确的结果展示给你看(这就是 Shadow Workspace 机制)。此外,帮你自动执行终端命令、一键应用 Diff 代码、分析你的项目目录树结构再传给模型,这些将“模型文本”转化为“编辑器实际动作”的基础设施系统,全部统称为 Harness
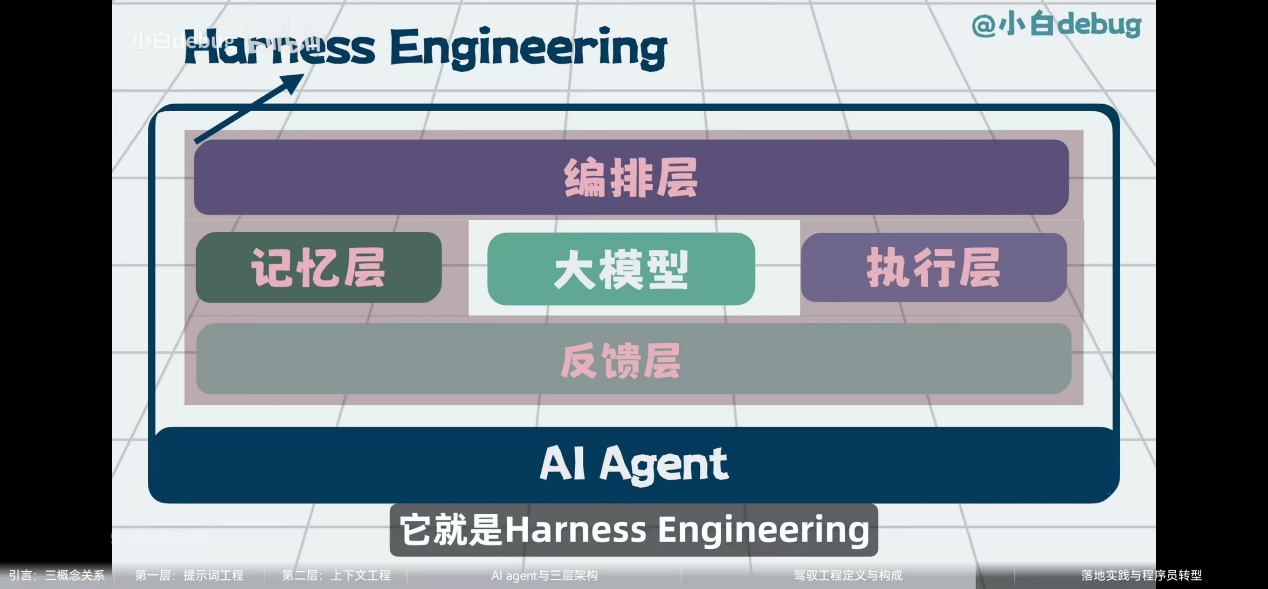
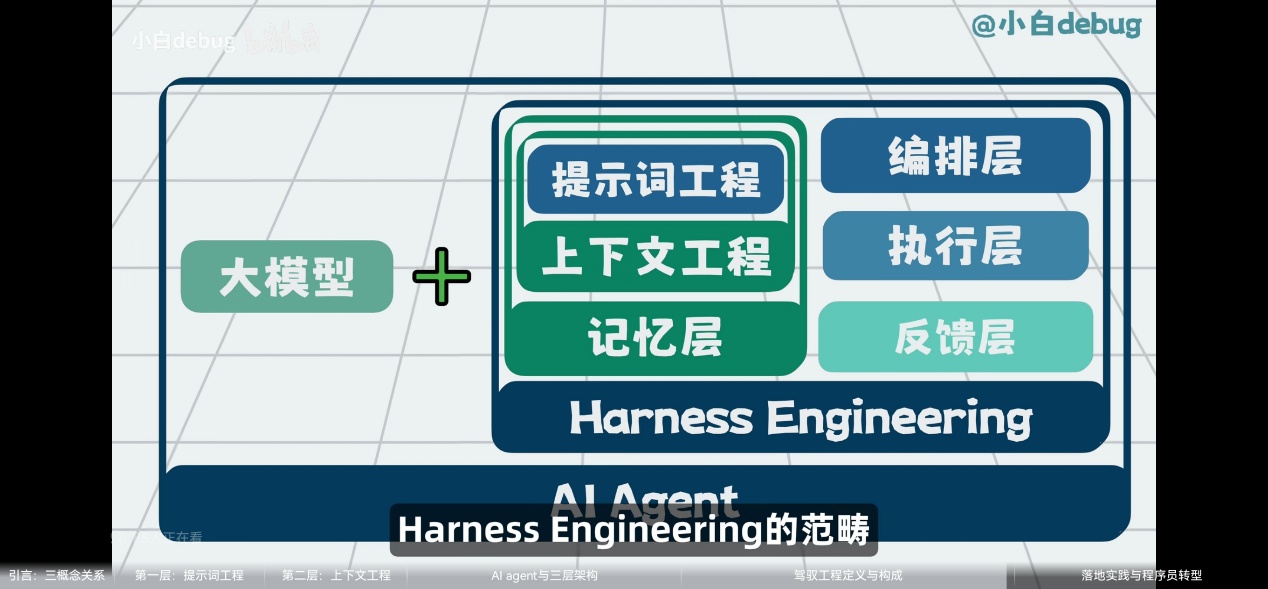
工程
资源包更新怎么提高效率(只有部分文件发生改变)
内容哈希(Content Hash): Webpack / Vite 打包时给文件名带上 Hash(如 app.a1b2.js)。只更新变动的文件,未变动的文件享受浏览器强缓存
拆包(Code Splitting): 将稳定的第三方库(Vendor)和业务代码分离,业务更新不影响依赖库缓存
差异化更新(增量更新 / BSDiff): 移动端/桌面端常见,下发 patch 补丁包,客户端合并新旧版本
Service Worker 预缓存: 结合 PWA(渐进式 Web 应用,Progressive Web App)策略,后台静默下载变动文件,下次打开秒开
出现偶发问题怎么排查(移动端)
留痕与上报: 接入自研日志系统,捕获报错堆栈、SourceMap 还原,记录用户前置行为轨迹(Breadcrumbs)
复现环境: 尽量还原机型、OS 版本、网络状态。利用移动端调试工具(vConsole, Eruda, Chrome Inspect)
控制变量与灰度: 采用二分法隔离代码,降级回滚。是否某种特定数据格式或临界条件引发
异常监控兜底: window.onerror / 资源加载失败 / 白屏监控(MutationObserver 检 DOM 树)
调研市场上现有的跨端框架,讲明方法步骤
- 明确核心诉求 (包体积、性能、生态、团队现有技术栈
Vue/React) - 市场盘点 (收集主流方案:
Flutter,React Native,UniApp,Taro,Capacitor) - 构建评估矩阵
- 性能表现: 渲染机制(
WebViewvs 原生控件 vs 自绘引擎) - 开发体验: 调试热更新、学习曲线
- 生态与基建: 社区活跃度、第三方库丰富度
DemoPoC验证(做个核心业务的最小可行性产品,测试踩坑)- 输出调研报告与选型建议